

How to Convert PDF to JSON Using Mailparser
1. Create your Mailparser inbox
First, sign up for a free trial. Upon doing so, you will get a prompt to create your first inbox. Mailparser acts as an inbox where you send emails that contain the data you need to extract — in this case, PDF attachments.
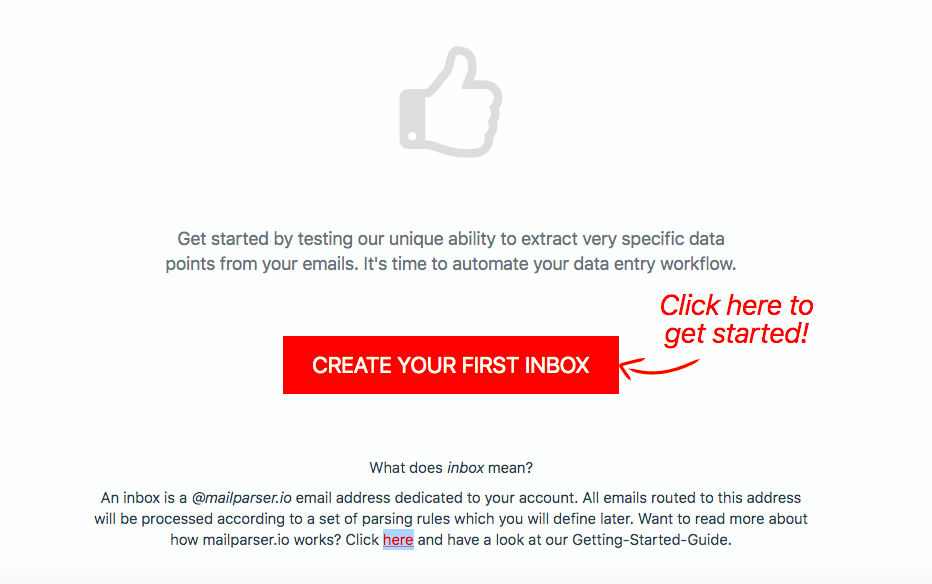
Click on ‘Create Your First Inbox’ then type a name for your inbox. You will get an email address for your Mailparser inbox.
2. Send an email with your PDF attached
Next, attach your PDF to an email and send it to your Mailparser address.
Back to Mailparser, you will find a confirmation that your email has reached your inbox along with a question. Select the option to the right: ‘Add Parsing Rules to Extract Data from Email Attachment’.
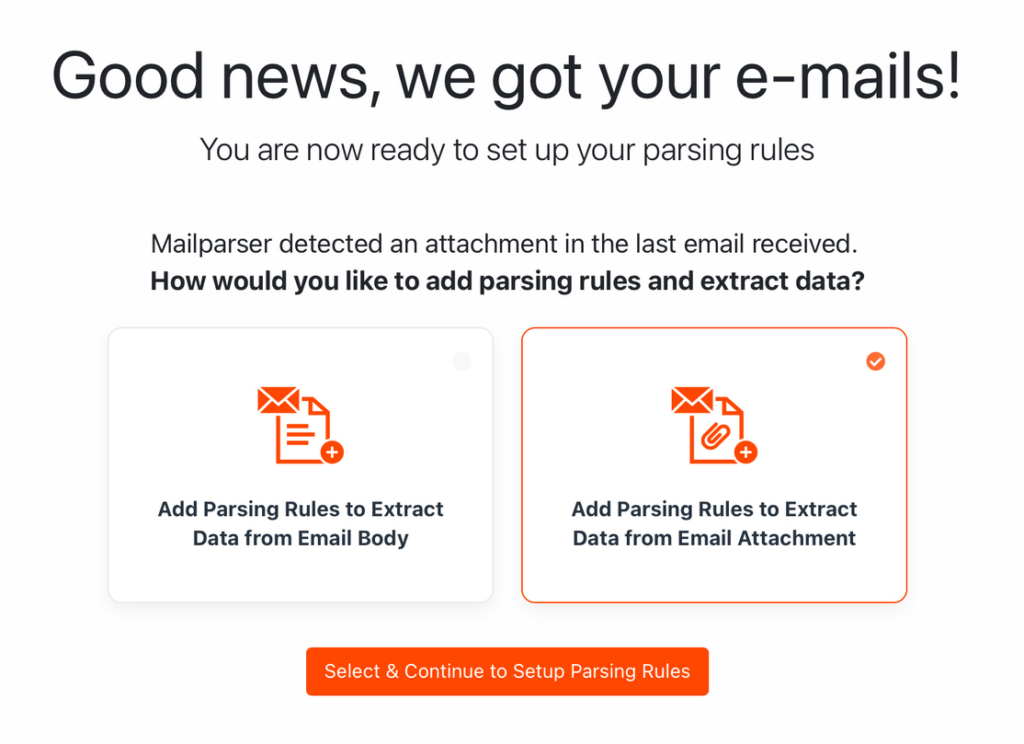
Click on ‘Select & Continue to Set Up Parsing Rules’.
3. Create parsing rules
Parsing rules are the instructions that Mailparser’s algorithms follow to identify each data field and extract it. You can try the Automatic Setup to get parsing rules for simple data fields or create parsing rules from scratch. Let’s create a couple of rules manually to show you how it works.
We have uploaded a PDF that contains employee information that we want in JSON format. First, let’s extract the employee ID.
Create the first parsing rule: employee ID
To do this, you want to go to the Rules section in the left-side panel and click on the button ‘Create a Parsing Rule’.
In the rule editor, first you have to select the data source, which is the attached PDF, so click on ‘Attachment’.
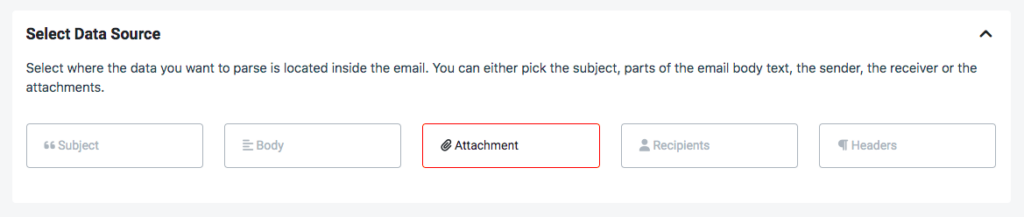
Scroll down and you’ll see that the text data in the PDF has been extracted. Now it’s just a matter of adding a filter or two to isolate the employee ID from the rest of the data. You can do this in a few clicks.
Click on the button ‘Add Text Filter’, move your cursor to ‘Set Start & End Position’, and click on the option ‘Find Start Position’.
Now, in the text field titled ‘Text match: after’, type ‘Employee ID: ’. This is the text that comes right before the actual employee ID, so we want the rule to extract the data that follows it. Don’t forget to type the blank space as well so that it’s not included in the parsed data.
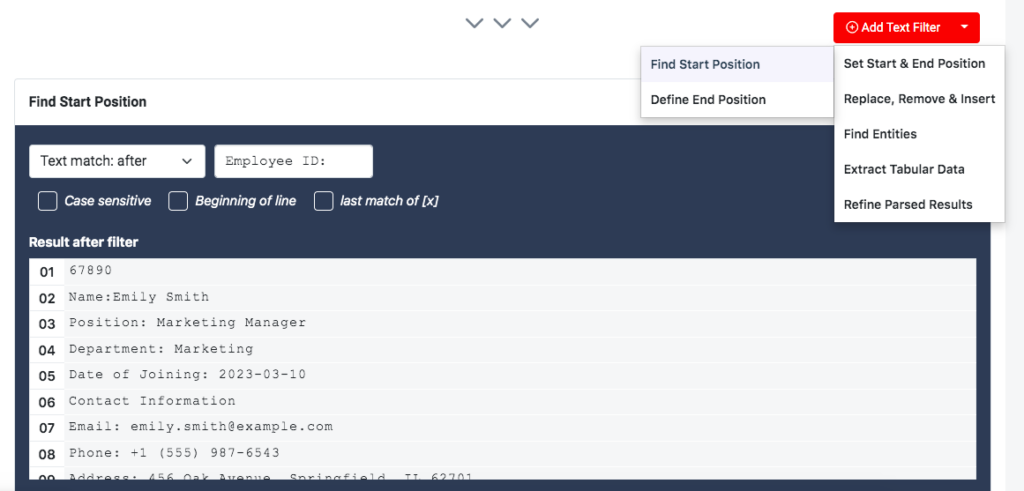
You will see in the results that the parsed data starts with the employee ID. Now, you just have to define the end position. Add a new text filter, go to ‘Set Start & End Position’, but this time click on the option ‘Define End Position’.
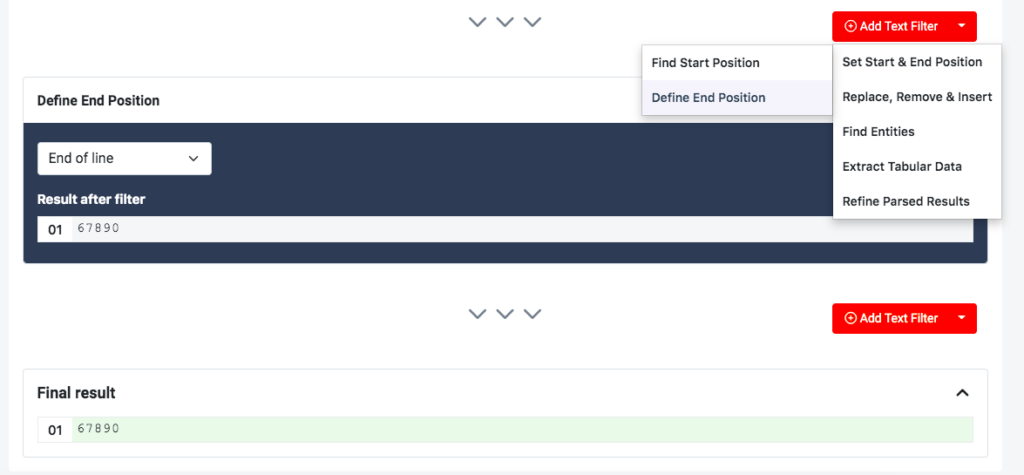
By default, this filter is set to ‘End of line’, so all the data that comes after the employee ID is removed.
We’re good here. Like we said, creating this rule only took a few clicks. Scroll down to the bottom of the editor and click on ‘Ok, looks good!’. Type a name for your rule e.g. Employee ID then click on ‘Save’.
Create the other parsing rules
You can repeat the same process to extract the other data fields: name, position, email, date of joining, base salary, bonus, etc.
Feel free to explore the various filter parameters to find the optimal setup for each parsing rule. Note that, in addition to text data, you can also extract tables and even customize their structure.
4. Download your JSON file
Alright, only a few clicks are left before you get your JSON file. Head over to the Downloads section in the left-side panel Click on the button that says ‘Create New Download Link’, then select the JSON format from the four download formats available.
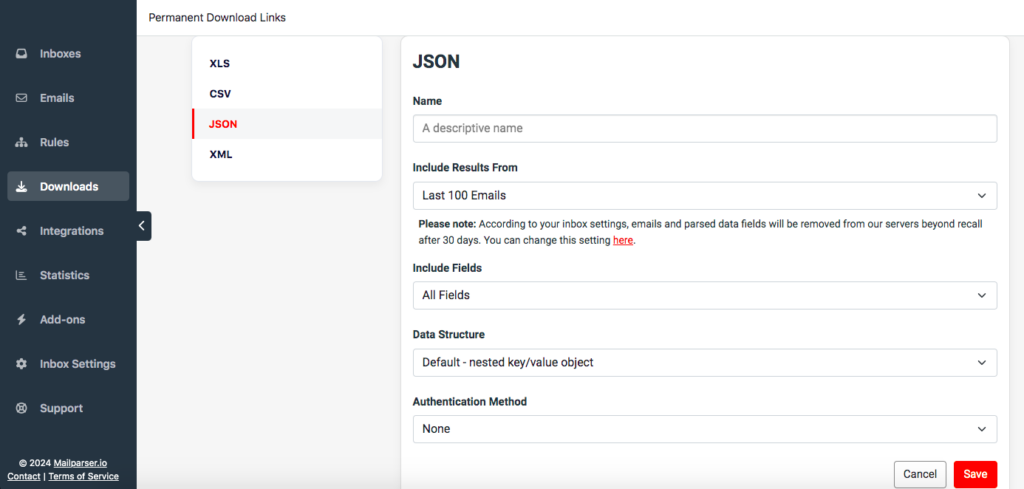
Type a name for your file and click on ‘Save’. You will get a download link; click on it and save your JSON file.
If we use a JSON viewer (like Firefox) to open the file, we can see the parsed data:

And that’s how you extract data from PDF to JSON using Mailparser. That was pretty simple, right?
4 Benefits of Using Mailparser to Extract Data from PDF to JSON
While Mailparser is not the only tool you can use to extract data from PDF to JSON, there are several reasons we believe it is the most fitting solution for your data extraction needs. Let’s elaborate a little.
No coding needed
Mailparser was built from day one to be a completely no-code parsing solution. So you don’t need to know how to write code in a language like Python in order to extract data from PDF to JSON.
Easy to use and customize
As shown in the previous section, you build your parsing rules in a simple point-a-click interface. Anyone can use Mailparser within minutes to extract data from PDFs and emails. And by taking a bit of time to customize the data extraction process, you will get accurate data that doesn’t require any cleaning up.
Unlike some other tools, you don’t have to commit to a high-tier plan to parse all pages in a PDF, and you’re not limited to parsing one PDF at a time only. In fact, you can send an email with several PDFs or several emails with a PDF attached to each. Either way, Mailparser will process all of them at the same time.
Save time and resources
The time savings enabled by automation are nothing short of massive. What would take several minutes can now be done in a few seconds, meaning you (and every other person who uses Mailparser) will save upwards of several hours per week.
In addition to saving the time that would go into data entry, you also save the time you will spend locating and rectifying data errors. Humans always experience a drop in attention to detail when a task is long and repetitive, but a PDF to JSON converter, once set up properly will deliver accurate data as long as the incoming PDF files have the same structure.
Streamline your workflows
As a web app with thousands of integrations possibilities, Mailparser will easily fit within your existing workflows. In addition to downloading parsed data in JSON format, you can download it in other formats and also export it to cloud apps and APIs through integrations.

This means you can seamlessly move information from PDFs to your systems and applications, which helps speed up processes such as employee onboarding, inventory management, financial analysis and reporting, etc. As a result, Your workflows will become more efficient, requiring less time, and you will avoid both bottlenecks and data errors.

