

How to Extract Data from PDF Files
Without further ado, follow these four simple steps to extract data from PDF files using Mailparser:
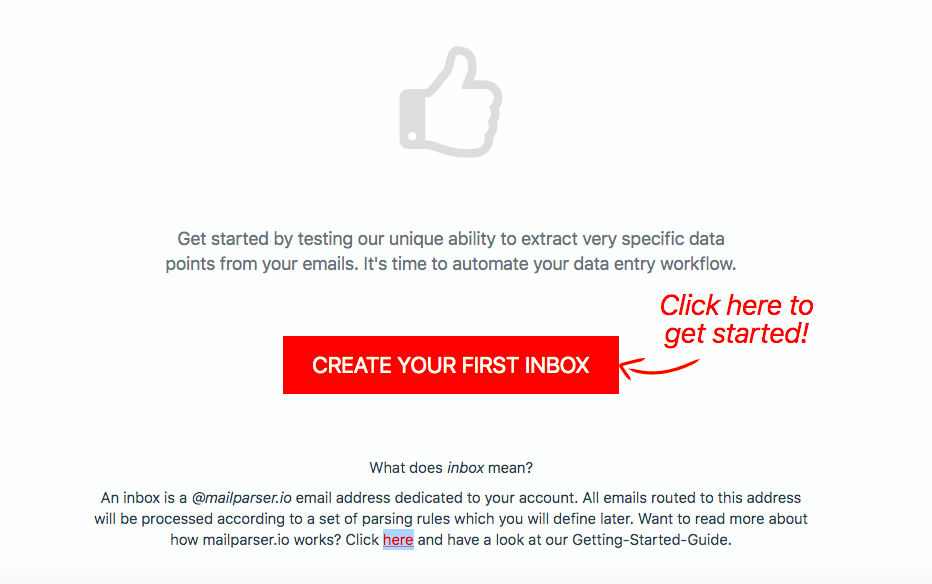
Step 1: Create a Mailparser inbox
To get started, sign up for a free trial. Upon creating your account, click on the button ‘Create Your First Inbox’. Type a name for your inbox and you will get an email address.
Step 2: Forward an email with your PDF attached to it
Next, attach your PDF document to an email and send it to your Mailparser inbox. A confirmation message will appear:
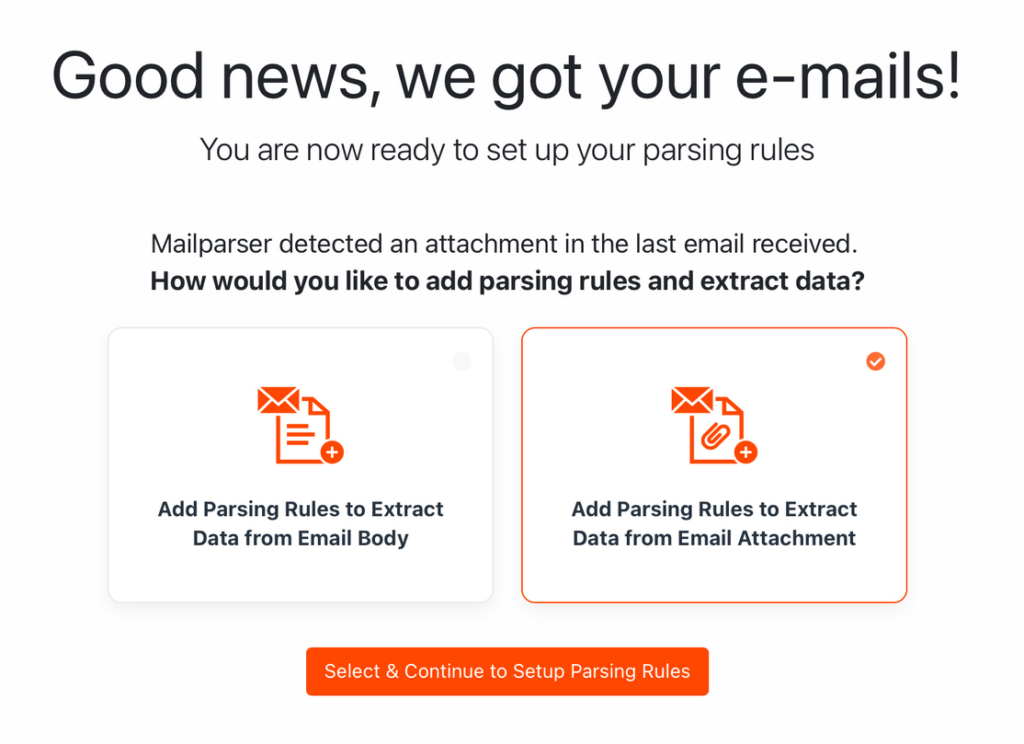
Select the option ‘Add Parsing Rules to Extract Data from Attachment’ and click on ‘Select & Continue to Setup Parsing Rules’.
Step 3: Create parsing rules
Parsing rules are the rules that Mailparser’s algorithms follow to identify and extract each data field. For this guide, we are using an invoice as an example.
Use the automatic setup
Upon processing the email, Mailparser will automatically try to create parsing rules.
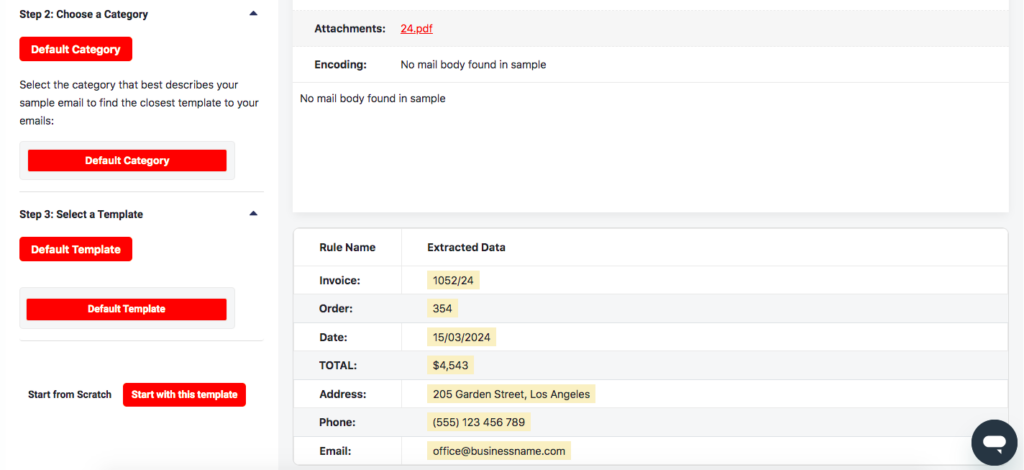
So right off the bat, we have several data fields that are already taken care of. Mailparser can extract information like the phone number and email address accurately and without any input from the user.
That said, we still need to extract one data field in the PDF, namely the line items. For now, click on the button ‘Start with this template’ at the bottom left.
After that, you will land on your dashboard. Click on the Rules section on the left-hand menu. There, you will see a list of all parsing rules. Click on ‘+ New Parsing Rule’ to add a new rule.
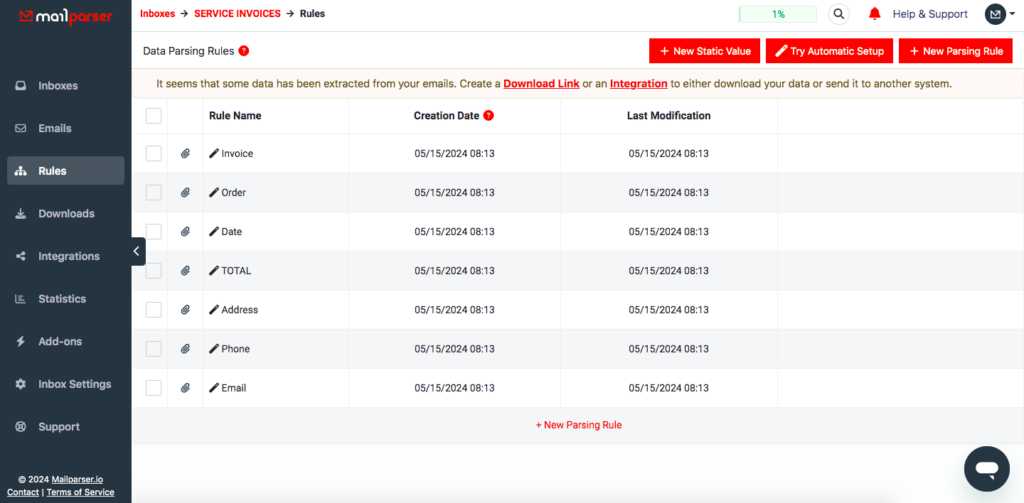
Pro tip: you can freely rename your parsing rules, change their order, or delete unneeded ones.
Create a custom rule to extract the line items
Select ‘Attachment’ as the data source and the rule editor will pull the contents of the document.
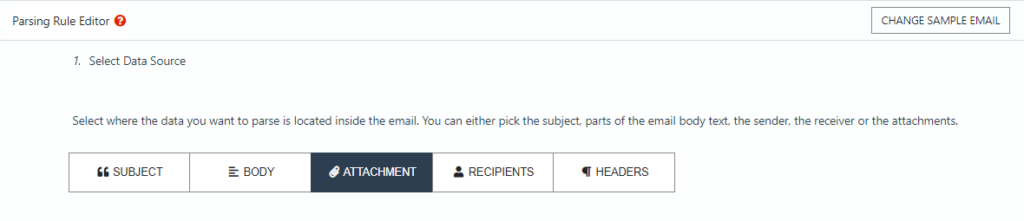
Now, to extract the line items, which is a table, all you have to do is click on the dropdown list called ‘Parse attachment’ and select the option ‘File content (Table Cells)’. Mailparser will extract the table in the document:
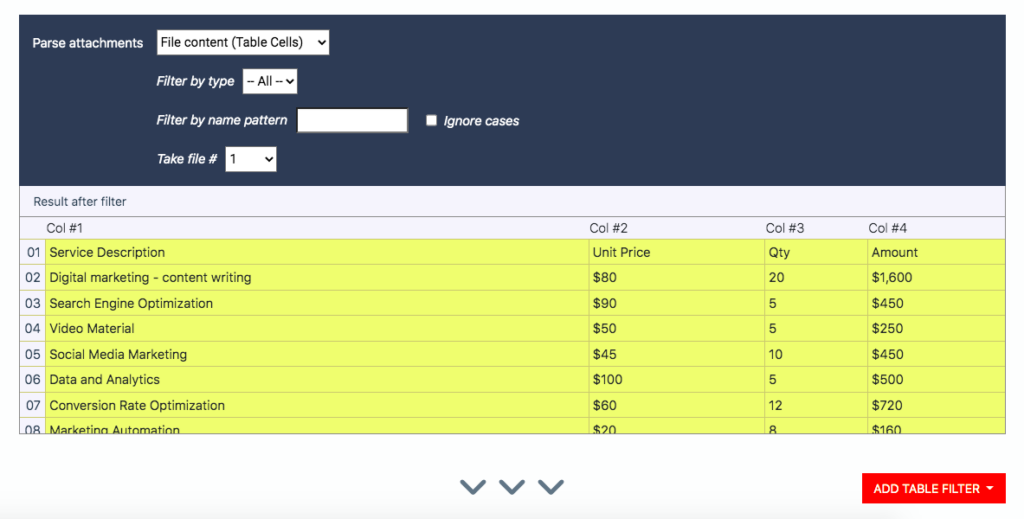
Great! The table retains its structure from the PDF and there are no data inaccuracies whatsoever.
Now, you can add table filters to refine the extracted data. In this case, you can remove the first row, remove the dollar signs, and add column headers outside the table itself.
Here is a quick example of adding a table filter. Click on the button ‘Add Table Filter’, hover your cursor over ‘Refine, Select & Insert’, and select the option ‘Remove Rows”.
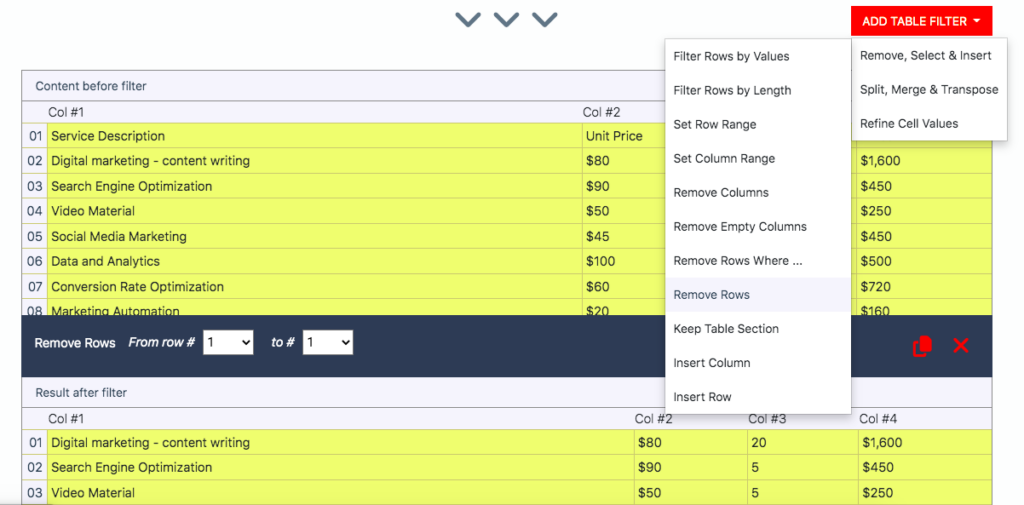
The filter will remove the first row by default. You can define the range of rows to remove depending on your case, though.
Feel free to add other table filters to refine your parsed data as you like. Once you’re done, scroll down to the bottom of your screen and click on the button ‘OK, Looks Good!’. Type a name for this rule (e.g. Line Items) and click on ‘Save & Validate’.
Step 4: Download or export parsed data
Download parsed data
Go to the Downloads section and choose the format you want: XLS, CSV, JSON, or XML. Tweak the download setting if needed and Mailparser will create a download link for you. Click on it and save your file.
Export parsed data
Go to the Integrations section and click on the button ‘Add New Integration’. Choose one of the integrations options — note that third-party integrations like Zapier allow you to connect your Mailparser account to thousands of cloud apps.
Follow the instructions provided, which — generally speaking — consist of logging in to your chosen app, selecting the desired destination, and mapping the parsed data fields with the corresponding data fields in your app.
So that’s how you extract data from PDF files using Mailparser. The whole process shouldn’t take more than a few minutes and will save you hundreds of hours over time.
Why You Need to Extract Data from PDF Documents
PDF documents are omnipresent in workplaces: invoices, forms, reports, shipping notes… They’re the go-to medium for sharing information internally and externally. However, since the data in a PDF is locked there, moving it to your business system can be a challenge. The most efficient way to do that is data extraction — here is why.
No time to enter data manually
Traditionally, people would simply type the information found in a PDF or copy and paste it into their system. This is fine if you only have a few documents, but when there are dozens of documents that you receive regularly, manual data entry becomes too time-consuming to stay viable.

Inputting data manually is at best boring, and can quickly become a nightmare. Imagine a huge volume of data that you need to enter under a tight deadline. Wouldn’t that be extremely stressful?
Plus, keep in mind that the average number of documents to process will only grow in the future.
Data errors create problems and cost a lot of money
In addition to the issue of time, manual data entry leads to a lot of errors in data such as figures in financial statements, inventory records, or customer information. Incorrect data, in turn, leads to many issues:
- Staying overtime to locate and rectify mistakes
- Inaccurate inventory data leads to a stock shortage and lost sales
- Embarrassing situations with customers
- A tarnished brand reputation
- Etc.
Your business needs timely and accurate data
Adequate data collection, management, and analysis are critical for the success of your business. Whether it’s monitoring inventory levels, providing customer support, analyzing sales trends, or understanding customer behavior, having timely and accurate data is necessary for your company to operate efficiently.
So you need to automate repetitive tasks, eliminate mistakes, and streamline access to information. That way, employees can perform their roles to the best of their ability. To achieve this, you have to move away from data entry and embrace data extraction.
Why Should I Use Mailparser?
There are countless tools out there that you can use to extract data from PDFs. So why choose Mailparser? Let’s answer this question.
Mailpaser is easy to use
For starters, Mailparser doesn’t require to be downloaded and installed — you can use it from any web browser.
Additionally, no coding knowledge is required either — anyone can use Mailparser to extract data successfully. As shown above, you create parsing rules and integrations on a simple point-and-click interface.
Furthermore, Mailparser is built to allow users to successfully extract data from not just one but multiple documents at once, whether it’s one email with several attachments or several emails with one or multiple attachments each.
Fully customizable parsing rules
What makes Mailparser stand out among other parsers is how customizable parsing rules are.
Other parsing tools, like PDF scrapers, may process your PDF files quickly, but the result may not be satisfying. You’ll probably have to spend time editing post-processed data, which goes against the purpose of extracting data in the first place. Some other tools require coding skills to customize the extraction process, which is anything but convenient.
Mailparser, on the other hand, lets you customize how you want a data field to be extracted, structured, and formatted. For example, you can format dates and phone numbers, filter table rows or columns according to specific criteria, calculate new table columns, and a lot more. So be sure to explore our text and table filter to get the perfect results you’re looking for.
Mailparser integrates with your favorite cloud apps and APIs
Another advantage of using Mailparser is the integration options. From Google Sheets to QuickBooks Online, Salesforce, and so many more, it’s easy to set up an action to be automatically done on your cloud app every time Mailparser parses PDF documents. For instance, a Salesforce integration can create a new record from new lead data, or a Slack integration can send a notification on a specific Slack channel with new contact requests.
You can also set up a webhook integration to send data to a URL endpoint. So take a look at our integrations and see which one fits your cloud stack.
Turn your PDFs into structured data in seconds
Once set up, Mailparser extracts data from any number of email attachments within seconds. So you will save hours of data entry every week. The time that you and your collaborators free up can then be used to perform more important tasks. On top of that, the cost of data entry will drastically go down, making automation far more cost-efficient than alternatives like outsourcing data entry.

The PDF format will no longer be a barrier to your workflows. Instead of locating files and opening them to input the needed data fields, your business system receives data that is accurate, well formatted, and structured properly. Truly, it doesn’t get much more convenient than that.
Use Case of PDF Data Extraction
Many of our users rely on Mailparser to extract data from PDF files quickly and without inaccuracies. Let’s take a quick look at a use case of PDF data extraction.
Julien Perreard is the Head of Digital & Online at The Giltedge Group, an award-winning travel agency based in South Africa. Here is how Julien describes how employees use Mailparser as a PDF data extractor:
“We get notified by email of all our client’s purchases with all details on a PDF attached to it. Thus, Mailparser allows us to save all of those as backup into Google Sheets & send all relevant info to Zapier where we have a Zap that notifies the right consultant about their client’s purchase. This also updates our CRM with that info that might become useful at a later stage should a client contact our consultant with an emergency issue.”
Julien added the following about how the Giltedge Group benefits from Mailparser:
“All of those processes above either didn’t exist, so we’re now providing extra benefits to our employees and/or clients, or were very manual – Mailparser allows us to automate the handling of the large amount of information generated during our customer’s journey from enquiry to purchase & travel.”

